


Giới thiệu
DBAhire là công ty chuyên nghiên cứu về những giải pháp cơ sở dữ liệu trên nền tảng mySQL, chúng tôi thành lập từ năm 2014, với 5 năm phát triển và nghiên cứu, DBAhire đã có nhiều dự án thành công, cung cấp nhiều giải pháp cũng như cập nhật những công nghệ mới nhất về mySQL, góp phần vào xây dựng nền tảng mySQL.
Với mong muốn phát triển hơn nữa, DBAhire cung cấp thêm một số dịch vụ lập trình như: thiết kế website, lập trình phần mềm,… với dữ liệu được xây dựng bằng mySQL mạnh mẽ, với những giải pháp mới giúp tối ưu truy xuất dữ liệu cho website và phần mềm, giúp giảm thời gian truy vấn data từ server.
Hy vọng với những gì mà chúng tôi đã làm được, cộng đồng có thể tiếp tục ủng hộ những dịch vụ cũng như nghiên cứu, đóng góp của DBAhire vào mã nguồn MySQL.

Dịch vụ
Lập trình website theo yêu cầu
Lập trình phần mềm theo yêu cầu
Lập trình ứng dụng iOS – Android
Dự án
Website
Phần mềm
iOS - Android
Khách hàng
Blog
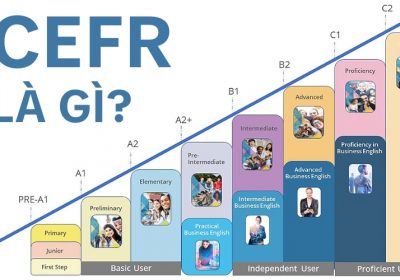
CEFR Là Gì? Tổng Quan, Các Cấp Độ Và Quy Đổi Điểm So Với IELTS

Tuổi Thọ Của Ghế Văn Phòng Là Bao Lâu? Khi Nào Cần Mua Mới?
